AI Incident Intelligence
| Company Personal Project |
Engine N/A |
||
| Platform Node.js / Docker Compose |
Skills Node.js, Apache Kafka, Cassandra 5, Google Gemini, GraphQL, Docker |
||
| Role Software Engineer |
Responsibilities Architecture, Implementation |
Overview
An event-sourced incident intelligence platform built around Kafka, Cassandra, MinIO, and GraphQL, with a Gemini-backed AI triage layer. The write path produces events to Kafka — the source of truth — and two independent consumer groups project those events into query-shaped Cassandra tables. Apollo Server serves the read side over GraphQL and a small REST surface.
Architecture
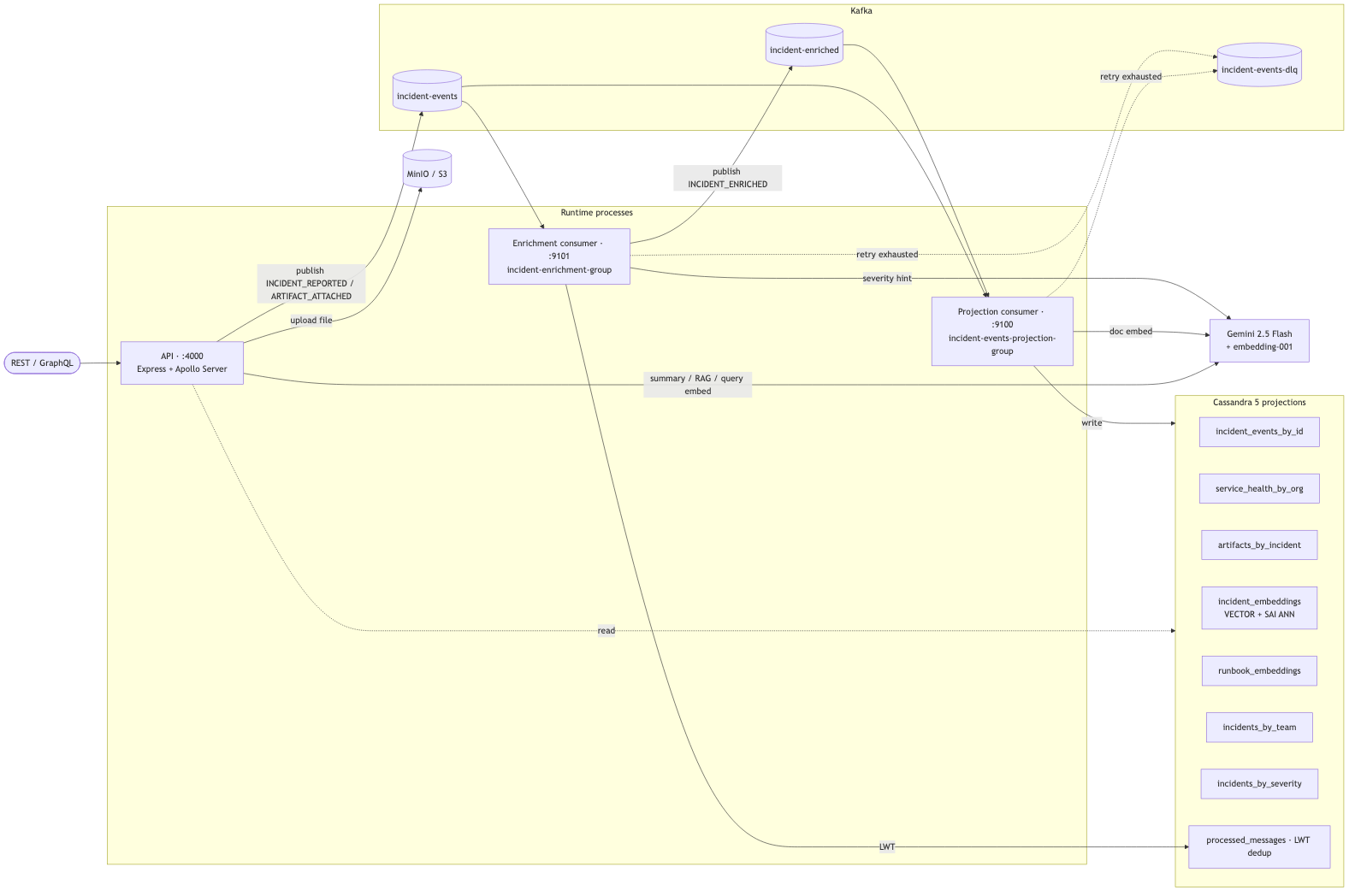
Kafka is the source of truth. The projection consumer subscribes to incident-events and incident-enriched and writes into query-optimized Cassandra tables (incident-by-id, by-team, by-severity, service-health, artifacts, embeddings). The enrichment consumer is an independent group on the same source topic — it computes team assignment, normalizes severity, and emits INCIDENT_ENRICHED to a separate topic. Decoupling the two means an enrichment outage cannot block the core read path.
End-to-End Demo
A single npm run demo script posts an incident, polls until both consumer groups have caught up, and exercises all three AI endpoints — the kind of trace I’d hand to a reviewer to prove the platform actually works end-to-end.
════════════════════════════════════════════════════════════════════════
AI Incident Intelligence — End-to-End Demo
════════════════════════════════════════════════════════════════════════
▶ Step 1/7 GET /health
✓ API reachable (12ms)
▶ Step 2/7 POST /incidents
incidentId: demo-1730000000000-pay
service: payments-api
severity: CRITICAL
✓ event published (id 7af3c1b2…) (38ms)
▶ Step 3/7 Wait for projection (Query.incidentTimeline)
→ projection consumer writes incident_events_by_id
✓ event landed in incident_events_by_id (612ms)
▶ Step 4/7 Wait for enrichment (Query.incidentsBySeverity)
→ enrichment consumer derives teamId, severityBucket, dayBucket
→ partition: (CRITICAL, 2026-04-27)
✓ row landed in incidents_by_severity (847ms)
▶ Step 5/7 POST /ai/incident-summary
→ Gemini structured-JSON output
✓ summary generated (1842ms)
▶ Step 6/7 POST /ai/similar-incidents (k=3)
→ Cassandra 5 SAI ANN cosine search over incident_embeddings
✓ returned 3 matches (489ms)
▶ Step 7/7 POST /ai/recommended-actions (k=3)
→ RAG: similar incidents + runbook chunks → Gemini
✓ returned 3 actions (2103ms)
════════════════════════════════════════════════════════════════════════
Demo complete in 6.2s
════════════════════════════════════════════════════════════════════════
Key Features
Structured AI incident summary
Gemini 2.5 Flash with a structured-JSON response schema — customer impact, likely root cause, a numeric confidence, ranked next actions, and the raw signals it pulled out of the timeline.
{
"summary": "Payments API timing out after 14:02 deploy; 18% error rate, p95 4.2s.",
"customer_impact": "Checkout funnel impacted; users unable to complete purchases.",
"likely_root_cause": "Postgres connection pool exhaustion after deploy.",
"confidence": 0.87,
"next_actions": [
"Roll back payments-api to the previous release",
"Inspect pg connection-pool sizing on payments-api",
"Page database on-call to check postgres-primary saturation"
],
"signals": [
"error_rate=18%",
"p95=4.2s",
"postgres-primary connection timeouts"
]
}
Similar-incident retrieval
Cosine ANN over 768-dim Gemini embeddings, indexed with Cassandra 5 SAI. The query message is embedded on the fly and the self-match is filtered out.
Top matches:
[score 0.912] inc-2024-08-payments-pool-exhaustion payments-api / CRITICAL
"Payments API connection pool exhausted after release; checkout failing."
[score 0.874] inc-2024-06-checkout-timeouts payments-api / HIGH
"Checkout endpoint timing out under load; postgres-primary saturated."
[score 0.831] inc-2024-03-pg-pool-leak orders-api / HIGH
"Connection pool leak in orders-api after switchover."
RAG-driven recommended actions
Similar incidents and the nearest runbook chunks are retrieved in parallel, then Gemini is asked for exactly three priority-sorted actions, each with a confidence and a risk rating.
{
"actions": [
{ "priority": 1, "action": "Roll back payments-api to the previous release",
"confidence": "HIGH", "risk": "LOW",
"reason": "Two retrieved runbooks and the closest similar incident all point at the deploy as the trigger." },
{ "priority": 2, "action": "Raise pg connection pool size on payments-api",
"confidence": "MEDIUM", "risk": "MEDIUM",
"reason": "Mitigates the symptom while the rollback is in flight; runbook db-pool-exhaustion.md recommends this as a holding action." },
{ "priority": 3, "action": "Page database on-call to inspect postgres-primary",
"confidence": "MEDIUM", "risk": "LOW",
"reason": "Repeated connection timeouts in the signal set warrant a primary health check." }
],
"notes": "Two of three retrieved runbooks point at pool exhaustion as the dominant pattern."
}
GraphQL + REST surface
Apollo Server (with Sandbox in dev) for the read side, Express REST endpoints for ingestion and the AI features. Both surfaces share the same resolvers underneath.
Implementation Highlights
- CQRS-style projections from a single Kafka source-of-truth topic, with two independent consumer groups
- Idempotent consumers with linear-backoff retry (3 attempts), LWT-backed dedup in
processed_messages, DLQ on exhaustion, and a manual replay tool - Compound partition key on
incidents_by_severity(severity_bucket,day_bucket) so theCRITICALbucket cannot grow into an unbounded partition - Best-effort embedding writes inside the projection consumer — a Gemini outage logs and skips, never blocking the core projection
- Per-message correlation IDs (
incidentId,eventId,topic,partition,offset) via pino, plus partition-awarekafka_consumer_lag_messagesgauge refreshed every 10s on Prometheus
The vector index lives directly in Cassandra 5 — no separate vector store, no extra moving piece in the deployment:
CREATE TABLE incident_embeddings (
incident_id text PRIMARY KEY,
org_id text,
service_name text,
severity text,
message text,
embedding VECTOR<FLOAT, 768>,
indexed_at timestamp
);
CREATE INDEX incident_embeddings_ann_idx
ON incident_embeddings (embedding)
USING 'sai'
WITH OPTIONS = {'similarity_function': 'cosine'};
Tech Stack
- Runtime: Node.js 18+, Express, Apollo Server
- Streaming: Apache Kafka (KRaft, single-node for local dev)
- Storage: Cassandra 5 with SAI vector index, MinIO for artifact blobs
- AI: Google Gemini 2.5 Flash +
embedding-001 - Observability: pino structured logging, prom-client metrics on three ports
- Tests: Jest integration test against the compose harness, plus per-feature smoke scripts
- Infra: Docker Compose (Kafka, Cassandra, Kafka UI, MinIO)